Hello and welcome to the second edition of the „Data Talks“ segment of the Data Science student blog. Today we have the honor to interview Piotr Zwiernik, who is assistant professor at Universitat Pompeu Fabra. Professor Zwiernik was recently awarded the Beatriu de Pinós grant from the Catalan Agency for Management of University and Research Grants. In the Data Science Master’s Program he teaches the maths brush-up and the convex optimization part of the first term class „Deterministic Models and Optimization“. Furthermore, he is one of the leading researchers in the field of Gaussian Graphical Models and algebraic statistics. We discuss his personal path, the fascination for algebraic statistic as well as the epistemological question of low-dimensional structures in nature.
Robert: First of all thank you very much for taking the time to talk to us. So let us start with the first question – Prof. Zwiernik, how did you get to where you are?
P. Z.: The pleasure is mine. Originally, I wanted to be a journalist and decided to study Economics. During this time I worked with Mas-Collel’s (one of BGSE’s founding fathers) classic textbook on Microeconomics and realized that I wasn’t that bad in maths. I chose to also study mathematics in Poland. Afterwards, I soon came to realize that I loved all algebraic subjects and especially algebraic geometry. Since I always wanted to combine subjects, I searched for different paths to synthesize algebra and statistics.
In 1998 the „magician“, Persi Diaconis, and Bernd Sturmfels, one of my later co-authors, published a beautiful paper, which introduced an efficient way of sampling from conditional distributions that generate specific sufficient statistics. Computational algebra provides a set of moves that allows us to connect the sampling space. Afterwards, one just has to run a standard MCMC algorithm such as Metropolis-Hastings. This beauty led to me focusing on the geometry of graphical models during my PhD studies in statistics at the University of Warwick.
At UC Berkely, during one of my many post-docs I was actually able to meet Professor Diaconis in person and had opportunity to participate in Michael Jordan’s working group. In Jordan’s group we read many papers, which covered completely different topics. But still we were able to find deep connections. This helped me realize, what people were really interested in. Nowadays, I tackle problems, which lie in the intersection of algebraic geometry and high-dimensional statistics.
Robert: How did your Economics background affect the path that you took and how does it influence your way of thinking?
P. Z.: First of all Economics introduced me to the field of Econometrics and statistics in general. Doing research in Econometrics also showed me the difference between theory and working with real data. We should never forget: Working with data is hard. Really hard.
One of my personal heroes is Terry Speed, who went through a very interesting transformation. He started of by studying pure geometry. Afterwards he got interested in statistics and cumulants. Only in the end he decided to work with real data and contributed research in the field of Bioinformatics. I can imagine traveling a similar path.
Robert: Can you tell us more about your post-doc time in the US? How did it compare to your experiences in Europe and did you feel pressured to succeed in the academic world?
P. Z.: In my mind the time of being a post-doc is the time of exploration. During mine I realized that everything is connected with each other. Hence, no time and effort is ever completely wasted. There is always something you can take away from studying a topic. It is extremely hard to do research if you constantly want to prove yourself. During the years I observed many colleagues, who burned themselves exactly because of this. The take-away message: Free exploration of the world is key and you should not stress yourself too much.
The academic world in the US is not very homogenous. Berkeley for example has a strong focus on optimization and Computer Science. Chicago and Seattle, on the other hand, specialize more on structural and algebraic problems – on how things really work.
Nandan: How do you define „making progress in understanding“?
P. Z.: This is a tough question and I will try to answer it with a recent example: Total positive distributions. One example of these can be found in so-called one-factor models, which are commonly used in psychometrics. Specific abilities (e.g. logical reasoning and spatial understanding) are assumed to be conditionally independent given a latent variable (e.g. intelligence). Usually these abilities are also positively correlated and this phenomenon seems to be characteristic for many natural systems. Sometimes it is only approximate (like Gaussianity), but still it is omnipresent. For example two undergraduate students of mine studied high-dimensional portfolio selection and were able to show that the covariance matrix of stocks exhibits strong traits of total positivity. This is only one example. Every few years it feels like I reach a new milestone of understanding.
Robert: Can you also give us a philosophical and intuitive understanding of your fascination for algebraic statistics?
P. Z.: Algebra is all about finding patterns in nature and different subfields of mathematics. The world is full of symmetrical relationships, which we try to detect. Thereby algebra simplifies and unifies the language, researchers use. Personally, I am interested in models that exhibit this symmetry property.
Gaussian Graphical Models are just one instance of this class of models. Another beautiful property of them is that there are many different ways, in which we can express them:
- They can be formulated from a statistical physics point of view. The joint distribution can be written as the product of factor functions.
- Furthermore, we can also express them with the help of classical graph theory. Nodes represent variables. Missing edges represent conditional independence relationships. Each graph represents a specific factorization of the joint distribution.
- Finally, they can also be studied as parametrized distributions such as in the exponential family setting. This allows us to make use of ideas from the theory of convexity, combinatorics and decomposable graphs.
There are endless connections, which brings me back to one of my previous points: Everything is related. Making connections and exploiting links is the way how we make progress.
Robert: In the previous year and in our convex optimization class we spoke a lot about penalized likelihood models and the underlying assumption of sparsity in nature. Do you think this assumption holds?
P. Z.: Not in the sense that the causal relationship between some variables has to be 0. But I believe in the hypothesis that nature’s underlying factors lie on a lower-dimensional manifold. Nature tends to fall in love with low-dimensional structures, which are not generic but very special. One such example is the Fibonacci Sequence. Low-dimensionality can have many different faces (e.g. sparsity or low-rank matrix factorizations). But often times people just assume the form, which is computationally tractable.
Nandan and Robert: You are also the organizer of the Statistics and Operations Research seminar at UPF. Can you tell us more about it, your future plans and the importance of a flourishing research community?
P. Z.: First of all, we have a very limited budget. This means that we are very much focused on inviting European researchers. Everyone knows Pompeu Fabra for its outstanding research in Economics. But not many people know us for our work in statistics or mathematics. Our overall goal is to change this. And our strategy is twofold: First, we invite strong senior researchers, who are great speakers. The speakers are exposed to the research group and the group can benefit from external stimuli. Second, we also invite young researchers, who work in fields close to our own. This gives them the opportunity to collaborate with us in the future and also helps us to increase our reach.
In the past we have had the fortune to host prominent guests such as Caroline Uhler (MIT), Wilfrid Kendall (Warwick) and Bin Yu (Berkeley). So we are slowly but surely progressing. For the future we want to invite more researchers. Also, the newly assembled Data Science Center is going to generate new sources of funding. We are hoping to be able to invite at least one very good speaker from the US per year.
Having a flourishing local community is extremely important! Our small group works extremely well together. For example, Eulalia Nualart, who is a theoretical probabilist, has written multiple papers with Christian Brownlees, who mainly researches in time series analysis. Mihalis Markakis and Gabor Lugosi started working on bandit problems together and in general there is a friendly and open atmosphere at UPF. All of us are doing very distinct things, so there are many opportunities to learn from each other.
Nandan and Robert: Lets wrap this up by asking you for your ultimate advice for all PhD students and aspiring Data Scientists? What do you wish you could have known earlier?
P. Z.: Don’t think about research as a way to prove yourself, but as an exploration process of the world. David Blackwell, one of the brightest statisticians ever, once said: „Basically, I’m not interested in doing research and I have never been. […] I’m interested in understanding, which is quite a different thing.“
Nandan and Robert: Thank you very much Professor Zwiernik!
References
Diaconis, Persi, and Bernd Sturmfels. “Algebraic algorithms for sampling from conditional distributions.” The Annals of statistics 26.1 (1998): 363-397.
Dudoit, Sandrine, ed. Selected Works of Terry Speed. Springer Science & Business Media, 2012.
 being the outcome space. The forecaster chooses an action
being the outcome space. The forecaster chooses an action 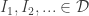 where
where 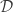 is the decision space and she has a loss at time
is the decision space and she has a loss at time  ,
, 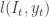 . To be concrete, in Example 1 the loss might be 1 if you either you went to the beach when raining or you were studying with sunny weather, 0 otherwise.
. To be concrete, in Example 1 the loss might be 1 if you either you went to the beach when raining or you were studying with sunny weather, 0 otherwise. 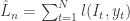 the cumulative loss of the forecaster. Without loss of generality we can impose that
the cumulative loss of the forecaster. Without loss of generality we can impose that ![l(I_t,y_t) \in [0,1]](https://s0.wp.com/latex.php?latex=l%28I_t%2Cy_t%29+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. 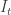 instead of action
instead of action 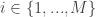 is defined as
is defined as 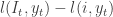 . A natural objective function is the average maximum regret faced by the forecaster, defined as:
. A natural objective function is the average maximum regret faced by the forecaster, defined as: 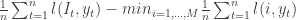 .
. of each expert
of each expert 
 without reveling it;
without reveling it; ;
;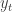 ;
;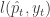 and each expert
and each expert  suffers a loss
suffers a loss 

 ,
,  ,
, 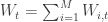 .
.  .
. 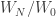 ) = log(
) = log(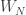 ) – log(
) – log( ) =
) =  . Then a lower bound can be defined as
. Then a lower bound can be defined as

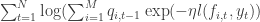 , with
, with 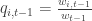 . Given that the loss is bounded between 0,1, by Hoeffding inequality:
. Given that the loss is bounded between 0,1, by Hoeffding inequality:

 . Rearrenging things we get
. Rearrenging things we get
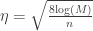 and by substituting the term we get:
and by substituting the term we get:
 over the set of M actions and draws an action
over the set of M actions and draws an action 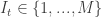 with
with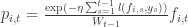
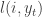
 with probability at least
with probability at least  .
. 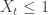 being a random variable such that
being a random variable such that ![E[X_t | \mathcal{F}_{t-1}]](https://s0.wp.com/latex.php?latex=E%5BX_t+%7C+%5Cmathcal%7BF%7D_%7Bt-1%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where  is the filtration at time
is the filtration at time 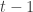 . Then by Hoeffding-Azuma inequality
. Then by Hoeffding-Azuma inequality ![P(\sum_{s=1}^n X_s - E[X_s] > t) \le \exp(-2t^2/n) \Rightarrow \sum_{s=1}^n X_s - E[X_s] \le \sqrt{\frac{n}{2} \text{log}(1/\delta)} \quad \text{w.p.} \ge 1 - \delta](https://s0.wp.com/latex.php?latex=P%28%5Csum_%7Bs%3D1%7D%5En+X_s+-+E%5BX_s%5D+%3E+t%29+%5Cle+%5Cexp%28-2t%5E2%2Fn%29+%5CRightarrow+%5Csum_%7Bs%3D1%7D%5En+X_s+-+E%5BX_s%5D+%5Cle+%5Csqrt%7B%5Cfrac%7Bn%7D%7B2%7D+%5Ctext%7Blog%7D%281%2F%5Cdelta%29%7D+%5Cquad+%5Ctext%7Bw.p.%7D+%5Cge+1+-+%5Cdelta++&bg=ffffff&fg=333333&s=0&c=20201002)
![P(\sum_{s=1}^n X_s - E[X_s] > t) \le \frac{E[\exp(\lambda \sum_s X_s)]}{\exp(\lambda t)}](https://s0.wp.com/latex.php?latex=P%28%5Csum_%7Bs%3D1%7D%5En+X_s+-+E%5BX_s%5D+%3E+t%29+%5Cle+%5Cfrac%7BE%5B%5Cexp%28%5Clambda+%5Csum_s+X_s%29%5D%7D%7B%5Cexp%28%5Clambda+t%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) for some
for some 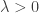 . By using the law of iterated expectations and by Hoeffding inequality
. By using the law of iterated expectations and by Hoeffding inequality![E[\exp(\lambda \sum_s^{n-1} X_s)E[\exp(\lambda X_n) | X_1,...X_{n-1}]]](https://s0.wp.com/latex.php?latex=E%5B%5Cexp%28%5Clambda+%5Csum_s%5E%7Bn-1%7D+X_s%29E%5B%5Cexp%28%5Clambda+X_n%29+%7C+X_1%2C...X_%7Bn-1%7D%5D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\le E[\exp(\lambda \sum_s^{n-1} X_s + \lambda^2/8)]](https://s0.wp.com/latex.php?latex=%5Cle+E%5B%5Cexp%28%5Clambda+%5Csum_s%5E%7Bn-1%7D+X_s+%2B+%5Clambda%5E2%2F8%29%5D+&bg=ffffff&fg=333333&s=0&c=20201002)
 times and get
times and get ![E[\exp(\lambda \sum_s X_s - \lambda t)] \le \exp(n\lambda^2/8 - \lambda t)](https://s0.wp.com/latex.php?latex=E%5B%5Cexp%28%5Clambda+%5Csum_s+X_s+-+%5Clambda+t%29%5D+%5Cle+%5Cexp%28n%5Clambda%5E2%2F8+-+%5Clambda+t%29&bg=ffffff&fg=333333&s=0&c=20201002) . Using this result and minimizing over
. Using this result and minimizing over  gives the result shown in the previous expression.
gives the result shown in the previous expression. ![\bar{l}(\mathbf{p}_t, y_t) = \sum_{t=1}^N p_{i,t}l(i, y_t) = E[l(I_t, y_t)|\mathcal{F}_{t-1}]](https://s0.wp.com/latex.php?latex=%5Cbar%7Bl%7D%28%5Cmathbf%7Bp%7D_t%2C+y_t%29+%3D+%5Csum_%7Bt%3D1%7D%5EN+p_%7Bi%2Ct%7Dl%28i%2C+y_t%29+%3D+E%5Bl%28I_t%2C+y_t%29%7C%5Cmathcal%7BF%7D_%7Bt-1%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where ![\sum_{t=1}^n [l(I_t, y_t) - \bar{l}(\mathbf{p}_t, y_t)] = 0](https://s0.wp.com/latex.php?latex=%5Csum_%7Bt%3D1%7D%5En+%5Bl%28I_t%2C+y_t%29+-+%5Cbar%7Bl%7D%28%5Cmathbf%7Bp%7D_t%2C+y_t%29%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002) has expectation
has expectation  . Using Hoeffding-Azuma
. Using Hoeffding-Azuma![\sum_{t=1}^n [l(I_t, y_t) - \bar{l}(\mathbf{p}_t, y_t)] \le \sqrt{\frac{n}{2}\text{log}(1/\delta)}](https://s0.wp.com/latex.php?latex=%5Csum_%7Bt%3D1%7D%5En+%5Bl%28I_t%2C+y_t%29+-+%5Cbar%7Bl%7D%28%5Cmathbf%7Bp%7D_t%2C+y_t%29%5D+%5Cle+%5Csqrt%7B%5Cfrac%7Bn%7D%7B2%7D%5Ctext%7Blog%7D%281%2F%5Cdelta%29%7D&bg=ffffff&fg=333333&s=0&c=20201002) w.p.
w.p. 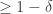 , therefore the loss are concentrated around expectation. Notice now that
, therefore the loss are concentrated around expectation. Notice now that 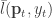 is convex (linear in this case) in the first variable. Therefore by the previous result
is convex (linear in this case) in the first variable. Therefore by the previous result
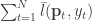 :
: 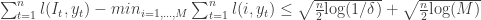 which concludes the proof.
which concludes the proof.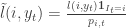
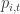 is the probability of choosing action
is the probability of choosing action  is the indicator variable equal to 1 if
is the indicator variable equal to 1 if  is true, 0 otherwise. Notice that
is true, 0 otherwise. Notice that ![E_t[\tilde{l}(i, y_t)] = \sum_{j=1}^M p_{j,t} \frac{l(i, y_t) \mathbf{1}_{i = j}}{p_{i,t}} = l(i,y_t)](https://s0.wp.com/latex.php?latex=E_t%5B%5Ctilde%7Bl%7D%28i%2C++y_t%29%5D+%3D+%5Csum_%7Bj%3D1%7D%5EM+p_%7Bj%2Ct%7D+%5Cfrac%7Bl%28i%2C+y_t%29+%5Cmathbf%7B1%7D_%7Bi+%3D+j%7D%7D%7Bp_%7Bi%2Ct%7D%7D+%3D+l%28i%2Cy_t%29+&bg=ffffff&fg=333333&s=0&c=20201002)
 the gain and
the gain and 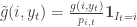 the estimated unbiased gain. Notice that
the estimated unbiased gain. Notice that  is at most 1, a property used for a martingale-type bound. Choose
is at most 1, a property used for a martingale-type bound. Choose 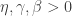 . Initialize
. Initialize  .
. 

 ;
;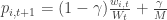 with exponential weights.
with exponential weights. we give up the unbiasedness of the estimate to guarantee that the estimated cumulative gains are, with
we give up the unbiasedness of the estimate to guarantee that the estimated cumulative gains are, with again. Therefore even without having no clue about what the loss would have been by going to new restaurants the strategy is consistent at optimal rate!
again. Therefore even without having no clue about what the loss would have been by going to new restaurants the strategy is consistent at optimal rate!
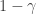 contains information regarding the losses of the actions taken in the past. The second term instead let the forecaster have non-zero probabilities for exploring new actions. In practice, the strategy give you a guide for how many times you should explore going to new restaurants and how many times you should go to good restaurants where you have already been.
contains information regarding the losses of the actions taken in the past. The second term instead let the forecaster have non-zero probabilities for exploring new actions. In practice, the strategy give you a guide for how many times you should explore going to new restaurants and how many times you should go to good restaurants where you have already been. ![\in [0,1]](https://s0.wp.com/latex.php?latex=%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , the actual price offered to the seller is
, the actual price offered to the seller is 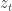 and the loss incurred by the seller at time
and the loss incurred by the seller at time 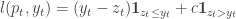
![c \in [0,1]](https://s0.wp.com/latex.php?latex=c+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . The seller can only observe whether the customer buys or not the product and has no clue about the empirical distribution of
. The seller can only observe whether the customer buys or not the product and has no clue about the empirical distribution of 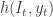 is reveled to the forecaster.
is reveled to the forecaster.![\mathbf{L} = [l(i,j)]_{N \times M}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BL%7D+%3D+%5Bl%28i%2Cj%29%5D_%7BN+%5Ctimes+M%7D&bg=ffffff&fg=333333&s=0&c=20201002) . With no loss of generality
. With no loss of generality ![l(I_t, y_t) \in [0,1]](https://s0.wp.com/latex.php?latex=l%28I_t%2C+y_t%29+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . At every iteration the forecaster chooses an action
. At every iteration the forecaster chooses an action  that assigns to each action/outcome pair
that assigns to each action/outcome pair 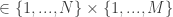 an element of a finite set
an element of a finite set  of signals. The values are collected in the feedback matrix
of signals. The values are collected in the feedback matrix ![\mathbf{H} = [h(i,j)]_{N \times M}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BH%7D+%3D+%5Bh%28i%2Cj%29%5D_%7BN+%5Ctimes+M%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Notice that the forecaster at time
. Notice that the forecaster at time 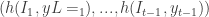 . In [1] the following strategy was shown to be Hannan consistent at a sub-optimal rate
. In [1] the following strategy was shown to be Hannan consistent at a sub-optimal rate  .
. 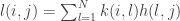 , that is
, that is 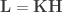 , considering
, considering 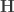 and
and ![[\mathbf{H} \quad \mathbf{L}]](https://s0.wp.com/latex.php?latex=%5B%5Cmathbf%7BH%7D+%5Cquad+%5Cmathbf%7BL%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) having the same rank. Define
having the same rank. Define 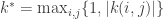 and as an unbiased estimator of the loss:
and as an unbiased estimator of the loss:
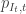 being the probability of having chosen action
being the probability of having chosen action 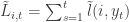 . Initialize
. Initialize 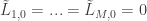 . For each round
. For each round 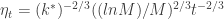 and
and 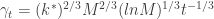 ;
; at random according to the distribution
at random according to the distribution 
 for all
for all 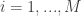
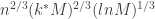 , that is with a convergency rate
, that is with a convergency rate 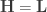 , the theorem leads to a bound of order
, the theorem leads to a bound of order 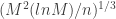 , much slower compared to the result obtained in the previous section. Finding the class of problems for which this bound can be improved remains in fact a challenging research question
, much slower compared to the result obtained in the previous section. Finding the class of problems for which this bound can be improved remains in fact a challenging research question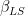 , from
, from 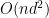 time to at least
time to at least 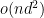 time. We reviewed two simple and fairly “slow” but powerful algorithms which simplified linear systems of equations with a large number of constraints (the classical
time. We reviewed two simple and fairly “slow” but powerful algorithms which simplified linear systems of equations with a large number of constraints (the classical  setting of tall data). The main idea was to preprocess the input matrix
setting of tall data). The main idea was to preprocess the input matrix 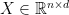 in such a way that we obtained a “representative” sketch in a lower dimensional space (
in such a way that we obtained a “representative” sketch in a lower dimensional space (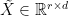 ). The term “representative” could be defined in two different ways and always with respect to the ultimate goal: a good approximation to the least squares (LS) solution. First, a good representation in a lower dimensional space could be interpreted as a subspace embedding that maintains pairwise distance up to an
). The term “representative” could be defined in two different ways and always with respect to the ultimate goal: a good approximation to the least squares (LS) solution. First, a good representation in a lower dimensional space could be interpreted as a subspace embedding that maintains pairwise distance up to an  -degree (via Johnson-Lindenstrauss transforms). This idea was the fundament of a random projection algorithm. Second, “representative” could be defined in terms of “leverage” on the LS fit. A natural measure was the so-called statistical leverage score, which could be extracted from the diagonal elements of the hat matrix or from the euclidean row norm of the orthonormal basis
-degree (via Johnson-Lindenstrauss transforms). This idea was the fundament of a random projection algorithm. Second, “representative” could be defined in terms of “leverage” on the LS fit. A natural measure was the so-called statistical leverage score, which could be extracted from the diagonal elements of the hat matrix or from the euclidean row norm of the orthonormal basis  for
for  computed from the QR decomposition or SVD.
computed from the QR decomposition or SVD.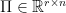 would take at least
would take at least  time (matrix-matrix multiplication). Since usually
time (matrix-matrix multiplication). Since usually 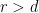 , we would not obtain an improvement.
, we would not obtain an improvement. -dimensional subspace, in which the leverage scores are uniformized. In this way we are able to sample rows uniformly at random. Secondly, it is also going to allow us to approximate the actual leverage scores in a fast way. Both concepts rely on Fast Fourier (or Hadamard-based) transforms. Ultimately, this is going to speed up computational complexity from
-dimensional subspace, in which the leverage scores are uniformized. In this way we are able to sample rows uniformly at random. Secondly, it is also going to allow us to approximate the actual leverage scores in a fast way. Both concepts rely on Fast Fourier (or Hadamard-based) transforms. Ultimately, this is going to speed up computational complexity from 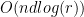 .
. by a vector
by a vector  and to do this in a reasonably fast way (faster than
and to do this in a reasonably fast way (faster than  and an orthogonal matrix
and an orthogonal matrix 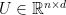 viewed as d vectors in
viewed as d vectors in  . A FJLT projects vectors fro
. A FJLT projects vectors fro 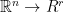 such that the orthogonality of U is preserved, and it does it quickly. I.e.,
such that the orthogonality of U is preserved, and it does it quickly. I.e., 
 we can compute
we can compute 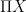 in
in 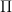 . So how can we define such a matrix? Ailon et al (2006) proposed the following Hadamard-based construction, which relies on fast Fourier/Hadamard preprocessing of the input matrix:
. So how can we define such a matrix? Ailon et al (2006) proposed the following Hadamard-based construction, which relies on fast Fourier/Hadamard preprocessing of the input matrix:
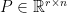 – Sparse JL matrix/Uniform sampling matrix (Achlioptas (2003), Frankl et al (1988)), where
– Sparse JL matrix/Uniform sampling matrix (Achlioptas (2003), Frankl et al (1988)), where 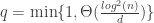

 – DFT or normalized Hadamard transform matrix: Structured so that Fast Fourier methods can be applied to compute them quickly. Setting
– DFT or normalized Hadamard transform matrix: Structured so that Fast Fourier methods can be applied to compute them quickly. Setting 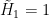 it is defined for all
it is defined for all  that are a power of two in a recursive fashion :
that are a power of two in a recursive fashion :![\displaystyle \tilde{H}_{2n} = \begin{bmatrix} \tilde{H}_{n} & \tilde{H}_{n} \\[0.3em] \tilde{H}_{n} & -\tilde{H}_{n} \end{bmatrix} \text{ and } H_n = \frac{\tilde{H}_n}{\sqrt{n}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctilde%7BH%7D_%7B2n%7D+%3D+%5Cbegin%7Bbmatrix%7D+%5Ctilde%7BH%7D_%7Bn%7D+%26+%5Ctilde%7BH%7D_%7Bn%7D+%5C%5C%5B0.3em%5D+%5Ctilde%7BH%7D_%7Bn%7D+%26+-%5Ctilde%7BH%7D_%7Bn%7D+%5Cend%7Bbmatrix%7D+%5Ctext%7B+and+%7D+H_n+%3D+%5Cfrac%7B%5Ctilde%7BH%7D_n%7D%7B%5Csqrt%7Bn%7D%7D%C2%A0&bg=ffffff&fg=000000&s=0&c=20201002)
 – Takes values
– Takes values  with probability
with probability 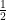 each: Preprocesses bad cases by randomization.
each: Preprocesses bad cases by randomization.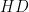 fulfills two very important tasks (Drineas et al, 3449, 2012): First, it essentially flattens spiky vectors (“spreads out its energy” – Drineas et al (3449, 2012)). Mathematically speaking, this means that we can bound the sup-norm of all transformed vectors by a quantity that is inversely proportional to
fulfills two very important tasks (Drineas et al, 3449, 2012): First, it essentially flattens spiky vectors (“spreads out its energy” – Drineas et al (3449, 2012)). Mathematically speaking, this means that we can bound the sup-norm of all transformed vectors by a quantity that is inversely proportional to  . This ultimately uniformizes the leverage scores (leverage scores will equal
. This ultimately uniformizes the leverage scores (leverage scores will equal 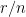 ). If
). If  allows us to construct an FJLT with high probability. Furthermore, computing the
allows us to construct an FJLT with high probability. Furthermore, computing the 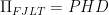 can be viewed as a subsampled randomized Hadamard transform (Drineas et al, 3449, 2012) or as a FJLT with high probability.
can be viewed as a subsampled randomized Hadamard transform (Drineas et al, 3449, 2012) or as a FJLT with high probability. with SVD
with SVD  and an
and an  -----------------------------------------------------------------------------------
Let
-----------------------------------------------------------------------------------
Let  be an
be an  with
with 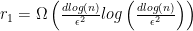 .
Compute
.
Compute 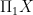 and its SVD/QR where
and its SVD/QR where  .
View the rows of
.
View the rows of  as n vectors in
as n vectors in  . Let
. Let  be an
be an 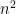 vectors, with
vectors, with 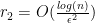 .
Return
.
Return  , an
, an 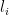 .
. . Afterwards one has to compute the SVD of the transformed matrix, before applying another regular JLT to
. Afterwards one has to compute the SVD of the transformed matrix, before applying another regular JLT to 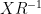 . The complexity of the algorithm can be decomposed in the following way:
. The complexity of the algorithm can be decomposed in the following way: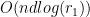 since
since 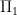 is an
is an 
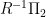 takes
takes 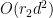 since
since 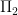 is an
is an 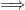 Overall:
Overall: 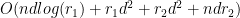
 ,
, 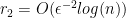 ,
,  ,
, 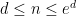 ), it follows that the algorithm has complexity
), it follows that the algorithm has complexity 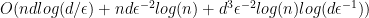 .
.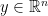 and an
and an 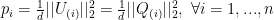 , where
, where  are the orthogonal matrices from either the SVD or the QR.
Randomly sample
are the orthogonal matrices from either the SVD or the QR.
Randomly sample  rows of
rows of  . Rescale them by
. Rescale them by 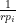 and form
and form 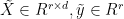 .
Solve
.
Solve 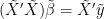 using any of the above mentioned algorithms.
Return
using any of the above mentioned algorithms.
Return 

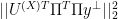 , which in turn can be used to bound the randomized residual sum of squares (see Drineas et al (2011) for complete proof). This again bounds the possible deviation the randomized estimator can take from the least-squares solution:
, which in turn can be used to bound the randomized residual sum of squares (see Drineas et al (2011) for complete proof). This again bounds the possible deviation the randomized estimator can take from the least-squares solution: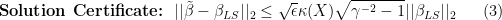

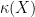 is the condition number of
is the condition number of  denotes the fraction of the norm of
denotes the fraction of the norm of 
 ). Afterwards I multiply with a five dimensional vector
). Afterwards I multiply with a five dimensional vector 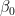 and add some
and add some 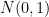 noise to obtain
noise to obtain 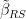 and take the euclidean norm of the difference. The resulting figure plots the histogram and a corresponding kernel estimator. The right figures, on the other hand, plots a comparison of a simple Cholesky decomposition based least squares estimator,
and take the euclidean norm of the difference. The resulting figure plots the histogram and a corresponding kernel estimator. The right figures, on the other hand, plots a comparison of a simple Cholesky decomposition based least squares estimator, 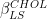 . The estimators in the first row randomly sample according to the leverage scores. We can directly see that the above theorem holds. More than 0.8 of the probability mass lies below 1. Hence, in at least 80 percent of the cases
. The estimators in the first row randomly sample according to the leverage scores. We can directly see that the above theorem holds. More than 0.8 of the probability mass lies below 1. Hence, in at least 80 percent of the cases  holds. Furthermore, it becomes apparent that the random sampling estimator does a way better job at approximating the estimator instead of the true data-generating vector
holds. Furthermore, it becomes apparent that the random sampling estimator does a way better job at approximating the estimator instead of the true data-generating vector 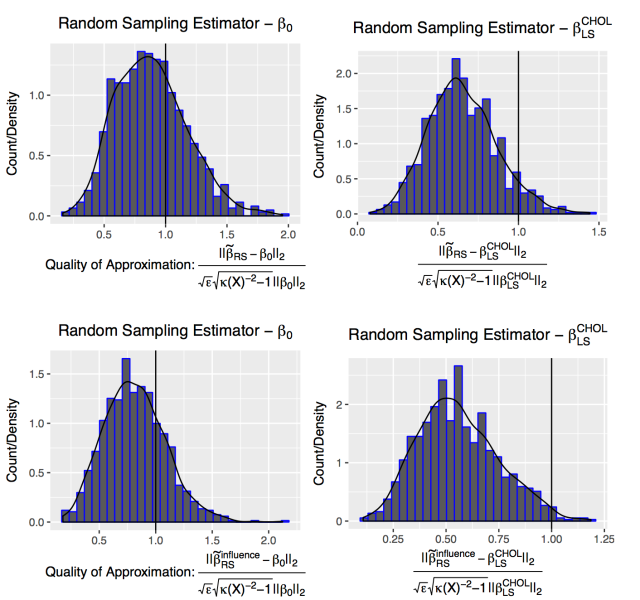
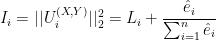
 . This seems only natural since we are constructing sketches of not only
. This seems only natural since we are constructing sketches of not only 


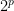 models). Instead of going the brute force way, one usually makes use of computational heuristics, which are clearly associated with short-comings. But what if we could sketch each model performance measure up to a certain degree of certainty?
models). Instead of going the brute force way, one usually makes use of computational heuristics, which are clearly associated with short-comings. But what if we could sketch each model performance measure up to a certain degree of certainty?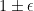 )-approximation of the objective. The top names in this field are Drineas, Kannan and Mahoney (2006 a,b,c). All of them have done pioneering work in the field of randomized algorithms for large matrices. Their work covers a whole branch of computational approximations such as randomized versions of matrix-matrix multiplication, least squares (LS), fast leverage score approximations and sparse matrix completion. The following two-part-series is mainly based on lecture notes of Mahoney (2016) and intends to introduce the audience to an alternative randomized perspective on solving the standard LS problem. Therefore, this article is going to review two simple (and fairly “slow”) but powerful ideas which simplify linear systems of equations with a large number of constraints (the classical
)-approximation of the objective. The top names in this field are Drineas, Kannan and Mahoney (2006 a,b,c). All of them have done pioneering work in the field of randomized algorithms for large matrices. Their work covers a whole branch of computational approximations such as randomized versions of matrix-matrix multiplication, least squares (LS), fast leverage score approximations and sparse matrix completion. The following two-part-series is mainly based on lecture notes of Mahoney (2016) and intends to introduce the audience to an alternative randomized perspective on solving the standard LS problem. Therefore, this article is going to review two simple (and fairly “slow”) but powerful ideas which simplify linear systems of equations with a large number of constraints (the classical 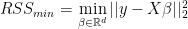
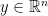 ,
,  . After “doing the math” (multiplying out, taking the gradient, yada yada) LS boils down to solving the following normal equations
. After “doing the math” (multiplying out, taking the gradient, yada yada) LS boils down to solving the following normal equations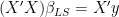
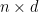 matrix
matrix  and
and  , which drastically reduces the amount of rows to
, which drastically reduces the amount of rows to 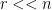 . Let’s write the transformed objective function as
. Let’s write the transformed objective function as 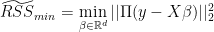 where
where 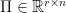 denotes some
denotes some 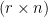 transformation matrix. Afterwards, we solve this reduced system and obtain the vector
transformation matrix. Afterwards, we solve this reduced system and obtain the vector  . There are two objectives which we intend to achieve:
. There are two objectives which we intend to achieve:

 denote the singular value decomposition of
denote the singular value decomposition of 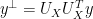 denote the residual vector, resulting from the fact that not all of
denote the residual vector, resulting from the fact that not all of 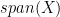 (Note
(Note 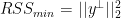 ).
).
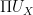 . This basically means that we want
. This basically means that we want 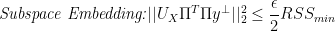
 . The second structural condition therefore requires that this orthogonality approximately “survives” the transformation. Hence,
. The second structural condition therefore requires that this orthogonality approximately “survives” the transformation. Hence,  has to be approximately orthogonal to
has to be approximately orthogonal to 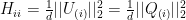 and hence we have a first potential randomized algorithm:
and hence we have a first potential randomized algorithm: , each of which is in
, each of which is in 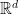 , let
, let 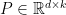 be such that
be such that
 and let
and let  be points in
be points in  defined as
defined as  .
Then if
.
Then if 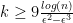 , for some
, for some 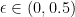 , then with probability at least 0.5,
all point-wise distances are preserved,
, then with probability at least 0.5,
all point-wise distances are preserved,  we have
we have

 , where
, where 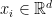 , an
, an 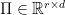 is a projection of the points
into
is a projection of the points
into  such that
such that

 and form
and form  )-approximation to the LS objective function value and an
)-approximation to the LS objective function value and an 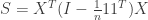 where
where 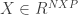 and
and 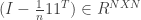 , where P is the number of variables and N the number of observations. Because the rank is bounded by the minimum of the rank of the two matrices, whenever P is greater then N the matrix is not full rank.
, where P is the number of variables and N the number of observations. Because the rank is bounded by the minimum of the rank of the two matrices, whenever P is greater then N the matrix is not full rank.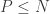 but their ratio is close to one, the problem is very likely to be ill-conditioned and different estimators are needed especially to compute the precision matrix. Intuitively, “S becomes unstable in the sense that small perturbations in measurements can lead to disproportionately large fluctuations in its entries” (Chi and Lange, 2014).
but their ratio is close to one, the problem is very likely to be ill-conditioned and different estimators are needed especially to compute the precision matrix. Intuitively, “S becomes unstable in the sense that small perturbations in measurements can lead to disproportionately large fluctuations in its entries” (Chi and Lange, 2014). , where
, where ![E[\sigma_{i,j}]](https://s0.wp.com/latex.php?latex=E%5B%5Csigma_%7Bi%2Cj%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) is replaced with its sample estimation. The researchers used asymptotic properties to justify their choice. On the other hand, as shown by Zhou et al, 2010, the rate of convergence under the Froebenius norm depends on the both the number of observation and the dimension of the problem. Therefore, we felt that in high dimensional settings a complementary approach in the context of portfolio risk minimization might be by estimating the weighting constant
is replaced with its sample estimation. The researchers used asymptotic properties to justify their choice. On the other hand, as shown by Zhou et al, 2010, the rate of convergence under the Froebenius norm depends on the both the number of observation and the dimension of the problem. Therefore, we felt that in high dimensional settings a complementary approach in the context of portfolio risk minimization might be by estimating the weighting constant  using cross validation. In a project developed by 4 current Data Science students, described in an upcoming article of this blog, they proposed the following methodology for portfolio risk minimization: every four months, they selected a sequence of alpha from 0 to 1, they computed the corresponding covariance matrix and the best capital allocation according to the given matrix. They kept the portfolio for the subsequent two months and then they computed the variance of the returns under the given portfolio during the two-months period. The process was repeated for daily returns of 800 random companies for a sample of 8000 companies from 2010 to 2016. They finally selected the lowest alpha leading to the lowest average out of sample variance. The best alpha was around 1/2, while for values lower then 0.44 the matrix was singular as expected. This methodology might be effective when the target loss function depends on some other model specification. On the other hand, this method has many computational limitations and it might be infeasible in many circumstances. In this context both missing values and the choice of the subsample might have had affected the result in an unknown way.
using cross validation. In a project developed by 4 current Data Science students, described in an upcoming article of this blog, they proposed the following methodology for portfolio risk minimization: every four months, they selected a sequence of alpha from 0 to 1, they computed the corresponding covariance matrix and the best capital allocation according to the given matrix. They kept the portfolio for the subsequent two months and then they computed the variance of the returns under the given portfolio during the two-months period. The process was repeated for daily returns of 800 random companies for a sample of 8000 companies from 2010 to 2016. They finally selected the lowest alpha leading to the lowest average out of sample variance. The best alpha was around 1/2, while for values lower then 0.44 the matrix was singular as expected. This methodology might be effective when the target loss function depends on some other model specification. On the other hand, this method has many computational limitations and it might be infeasible in many circumstances. In this context both missing values and the choice of the subsample might have had affected the result in an unknown way.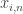 can be described as:
can be described as: 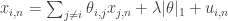 , where
, where 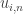 is gaussian noise centered on zero. By assuming for the moment that
is gaussian noise centered on zero. By assuming for the moment that 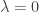 , we can identify a projection matrix
, we can identify a projection matrix 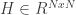 containing the coefficients
containing the coefficients  such that
such that  and where
and where  is a vector of residuals,
is a vector of residuals,  is the identity matrix and X is a vector of observed values. Taking the variance of the residuals we know that:
is the identity matrix and X is a vector of observed values. Taking the variance of the residuals we know that: 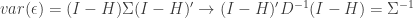 where D is a diagonal matrix containing the variance of the residuals. It can be shown that we can express the off diagonal elements of H as a function of the precision matrix K:
where D is a diagonal matrix containing the variance of the residuals. It can be shown that we can express the off diagonal elements of H as a function of the precision matrix K: 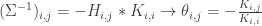 . This properties have been exploited in many settings. Pourahmadi et al. proposed a parametrization of the concentration matrix using the generalized Cholesky decomposition for time serie analysis. For time series, the coefficient
. This properties have been exploited in many settings. Pourahmadi et al. proposed a parametrization of the concentration matrix using the generalized Cholesky decomposition for time serie analysis. For time series, the coefficient  is the auto-regressive coefficient, where each serie is regressed on the previous observations. The generalized Cholesky decomposes the matrix into LDL, where L is a triangular matrix with ones elements on the diagonal and D is a diagonal matrix. The matrix L can be interpreted as the matrix
is the auto-regressive coefficient, where each serie is regressed on the previous observations. The generalized Cholesky decomposes the matrix into LDL, where L is a triangular matrix with ones elements on the diagonal and D is a diagonal matrix. The matrix L can be interpreted as the matrix  , containing the negative coefficients on the off-diagonal elements of the upper triangle, ones on the diagonal – each observations is not regressed on itself- and zero in the remaining entries. The matrix D instead is the positive diagonal matrix containing the residuals variance. By imposing
, containing the negative coefficients on the off-diagonal elements of the upper triangle, ones on the diagonal – each observations is not regressed on itself- and zero in the remaining entries. The matrix D instead is the positive diagonal matrix containing the residuals variance. By imposing 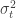 , the residual variance for each observation at time t, and the regression coefficients. Interestingly, the best tuning parameter
, the residual variance for each observation at time t, and the regression coefficients. Interestingly, the best tuning parameter ![log[det(\Theta)] - tr(S \Theta)](https://s0.wp.com/latex.php?latex=log%5Bdet%28%5CTheta%29%5D+-+tr%28S+%5CTheta%29&bg=ffffff&fg=333333&s=0&c=20201002) where S is the sample covariance matrix and
where S is the sample covariance matrix and 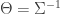 . According to Tibshirani et al., 2008, we can express the problem by imposing an additional term representing a penalty on the sum of the L1 norms of the entries. The imposition of the penalty ensure sparsity whenever the tuning parameter is large enough.
. According to Tibshirani et al., 2008, we can express the problem by imposing an additional term representing a penalty on the sum of the L1 norms of the entries. The imposition of the penalty ensure sparsity whenever the tuning parameter is large enough.
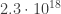

 pairs of students in each WHILE loop. In the worst case, the algorithm could start from the worst possible solution and in each WHILE loop iteration only move to the next-best solution, thus leading to brute-force-like performance.
pairs of students in each WHILE loop. In the worst case, the algorithm could start from the worst possible solution and in each WHILE loop iteration only move to the next-best solution, thus leading to brute-force-like performance.
